初识布隆过滤器BloomFilter
初步认识一下布隆过滤器 BloomFilter,了解它的原理、应用场景、优缺点、Java 中的使用,以及初步查看 Guava 包中一些方法的实现源码。
# 什么是布隆过滤器?
布隆过滤器(英语:Bloom Filter)是 1970 年由一个叫布隆的小伙子提出的。
它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用来判断一个元素是否在一个集合中,很常用的一个功能是用来去重。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
# Bloom Filter 应用场景
在爬虫中常见的一个需求:目标网站 URL 千千万,怎么判断某个 URL 爬虫是否宠幸过?简单点可以爬虫每采集过一个 URL,就把这个 URL 存入数据库中,每次一个新的 URL 过来就到数据库查询下是否访问过。
select id from table where url = 'https://bingozb.github.io'
但是随着爬虫爬过的 URL 越来越多,每次请求前都要访问一次数据库,并且对于这种字符串的 SQL 查询效率并不高。
除了数据库之外,使用 Redis 的 set 结构也可以满足这个需求,并且性能优于数据库。但是 Redis 也存在一个问题:耗费过多的内存。
这个时候布隆过滤器就很豪横的出场了:这个问题让我来。
相比于数据库和 Redis,使用布隆过滤器可以很好的避免性能和内存占用的问题。
# Bloom Filter 原理
当一个元素加入布隆过滤器中的时候,通过 K 个哈希函数对这个元素进行 K 次计算,得到 K 个哈希值,然后根据得到的哈希值,在位数组中把对应下标的元素值置为 1。
要判断一个值是否在布隆过滤器中,对元素再次进行哈希计算,得到 K 个哈希值,然后判断位数组对应下标的这些点是不是都是1,就(大约)可以知道集合中有没有它:
- 如果这些点有任何一个
0,则被检元素一定不存在; - 如果这些点都是
1,则被检元素很可能存在。
这就是布隆过滤器的基本思想。
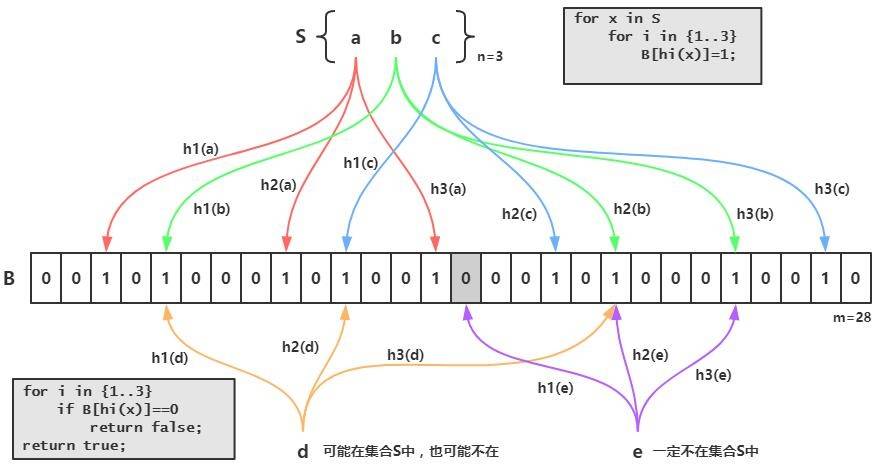
布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit,每个元素只能是 0 或者 1。
这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间。
# Bloom Filter 优点
全量存储但不存储元素本身,在某些保密要求非常严格的场合有优势
空间效率高
插入/查询时间都是常数,远远超过一般算法。
# Bloom Filter 缺点
bloom filter 之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性。
存在误判:要查找的元素并没有在容器中,但是可能 hash 之后得到的 k 个位置上的值也都是 1。
删除困难:一个放入容器的元素映射到 bit 数组的 k 个位置上是 1,删除的时候不能简单的直接置为 0,可能会影响其它元素的判断。(可以采用 Counting Bloom Filter)
# Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava 中就提供了一种 Bloom Filter 的实现。
- 在使用 bloom filter 时,绕不过的两点是预估数据量 n 以及期望的误判率 fpp。
- 在实现 bloom filter 时,绕不过的两点就是 hash 函数的选取以及 bit 数组的大小。
对于一个确定的场景,我们预估要存的数据量为 n,期望的误判率为 fpp,然后需要计算我们需要的 Bit 数组的大小 m,以及 hash 函数的个数 k,并选择 hash 函数。
# Bit 数组大小选择
根据预估数据量 n 以及误判率 fpp,bit 数组大小的 m 的计算方式:
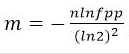
# 哈希函数选择
由预估数据量 n 以及 bit 数组长度 m,可以得到一个 hash 函数的个数 k:
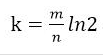
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个 Bit。
选择 k 个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入 k 个不同的参数。
哈希函数个数 k、位数组大小 m、加入的字符串数量 n 的关系可以参考:
# Java 使用 BloomFilter
要使用 BloomFilter,需要引入 guava 包,这里使用 Maven:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
2
3
4
5
测试分两步:
1、往过滤器中放一百万个数,然后验证这一百万个数是否都能通过过滤器,不能通过的有多少个。
2、另外找一万个数,然后验证这一万个数是否也能通过过滤器,能通过的有多少个。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class TestBloomFilter {
private static int total = 1000000;
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
// private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.001);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
int errorCount1 = 0;
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
errorCount1++;
}
}
System.out.println("测试1 - 匹配不上的数量:" + errorCount1);
// 匹配不在过滤器中的10000个值,有多少被匹配上
int errorCount2 = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
errorCount2++;
}
}
System.out.println("测试2 - 误匹配上的数量:" + errorCount2);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
运行程序,控制台打印结果:
测试1 - 匹配不上的数量:0
测试2 - 误匹配上的数量:320
2
运行结果表示,遍历这一百万个在过滤器中的数时,都被识别出来了。而一万个不在过滤器中的数,误判了 320 个,错误率是 0.03 左右。
# 查看 BloomFilter 源码
BloomFilter 并没有公有的构造函数,只有一个私有构造函数,而对外它提供了 5 个重载 create 方法。
由于我们调用 BloomFilter.create 第二个参数传的是 int 类型,所以首先来到这个方法:
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long)expectedInsertions);
}
2
3
这个方法把第二个参数从int强制转换为long类型,然后直接调用另一个 create 方法:
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
2
3
而这个方法又是直接调用另一个 create 方法,传多了第三个参数,值为0.03D,这就是默认的”误判率“,也就是3%。
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
2
3
到这依然还是再调用另外一个 create 方法,也是最终的 create 方法,传多了第四个参数 strategy。
@VisibleForTesting
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, BloomFilter.Strategy strategy) {
Preconditions.checkNotNull(funnel);
Preconditions.checkArgument(expectedInsertions >= 0L, "Expected insertions (%s) must be >= 0", expectedInsertions);
Preconditions.checkArgument(fpp > 0.0D, "False positive probability (%s) must be > 0.0", fpp);
Preconditions.checkArgument(fpp < 1.0D, "False positive probability (%s) must be < 1.0", fpp);
Preconditions.checkNotNull(strategy);
if (expectedInsertions == 0L) {
expectedInsertions = 1L;
}
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException var10) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", var10);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
BloomFilter.Strategy 是一个接口,它继承了 Serializable 接口,接口中就有我们刚使用的方法。
interface Strategy extends Serializable {
<T> boolean put(T var1, Funnel<? super T> var2, int var3, LockFreeBitArray var4);
<T> boolean mightContain(T var1, Funnel<? super T> var2, int var3, LockFreeBitArray var4);
int ordinal();
}
2
3
4
5
6
7
而倒数第二个 create 方法中,传的 strategy 参数的值是 BloomFilterStrategies.MURMUR128_MITZ_64,我们再看一下 BloomFilterStrategies。
enum BloomFilterStrategies implements Strategy {
MURMUR128_MITZ_32 {
public <T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.LockFreeBitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int)hash64;
int hash2 = (int)(hash64 >>> 32);
boolean bitsChanged = false;
for(int i = 1; i <= numHashFunctions; ++i) {
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
bitsChanged |= bits.set((long)combinedHash % bitSize);
}
return bitsChanged;
}
public <T> boolean mightContain(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.LockFreeBitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int)hash64;
int hash2 = (int)(hash64 >>> 32);
for(int i = 1; i <= numHashFunctions; ++i) {
int combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
if (!bits.get((long)combinedHash % bitSize)) {
return false;
}
}
return true;
}
},
MURMUR128_MITZ_64 {
public <T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = this.lowerEight(bytes);
long hash2 = this.upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for(int i = 0; i < numHashFunctions; ++i) {
bitsChanged |= bits.set((combinedHash & 9223372036854775807L) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
public <T> boolean mightContain(T object, Funnel<? super T> funnel, int numHashFunctions, BloomFilterStrategies.LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = this.lowerEight(bytes);
long hash2 = this.upperEight(bytes);
long combinedHash = hash1;
for(int i = 0; i < numHashFunctions; ++i) {
if (!bits.get((combinedHash & 9223372036854775807L) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private long lowerEight(byte[] bytes) {
return Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private long upperEight(byte[] bytes) {
return Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
};
// 以下省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
可以看到 BloomFilterStrategies 是一个枚举类,实现了 Strategy 接口,两个的枚举对象都实现了 Strategy 接口的 put 和 mightContain 方法。
MURMUR128_MITZ_32 和 MURMUR128_MITZ_64 分别对应了 32 位哈希映射函数,和 64 位哈希映射函数,后者使用了 murmur3 hash 生成的所有 128 位字节数组,具有更大的空间,不过原理是相通的,我们选择默认的 MURMUR128_MITZ_64 来分析。
抽象来看,put是写,mightContain是读,两个方法的代码有一点相似,都是先利用 murmur3 hash 对输入的 funnel 计算得到 128 位的字节数组,然后高低分别取 8 个字节(64位)创建 2 个 long 型整数 hash1,hash2 作为哈希值。
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = this.lowerEight(bytes);
long hash2 = this.upperEight(bytes);
2
3
4
private long lowerEight(byte[] bytes) {
return Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private long upperEight(byte[] bytes) {
return Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
2
3
4
5
6
7
循环体内采用了 2 个函数模拟其他函数的思想,这相当于每次累加hash2,然后通过基于 bitSize 取模的方式在 bit 数组中索引。
boolean bitsChanged = false;
long combinedHash = hash1;
for(int i = 0; i < numHashFunctions; ++i) {
bitsChanged |= bits.set((combinedHash & 9223372036854775807L) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
2
3
4
5
6
7
8
这里的 9223372036854775807L 实际上是 Long.MAX_VALUE,之所以要和 Long.MAX_VALUE 进行按位与的操作,是因为在除数和被除数符号不一致的情况下计算所得的结果是有差别的。
在程序语言里,% 准确来说是取余运算(C,C++ 和 Java 均如此,python 是取模),例如 -5 % 3 = -2。
而取模的数学定义是 x mod y = x - y[x/y],[x/y]向下取整,所以:
-5 mod 3
= -5 - 3 * [-5/3]
= -5 - 3 * (-2)
= -5 + 6
= 1
2
3
4
5
因此当哈希值为负数的时候,其取余的结果为负(因为bitSize始终为正数),这样就不方便在 bit 数组中取值,因此通过 Long.MAX_VALUE (二进制为0111…1111),直接将开头的符号位去掉,从而转变为正数。当然也可以取绝对值,在另一个MURMUR128_MITZ_32的实现中就是这么做的。
在put方法中,先是将索引位置上的二进制置为1,然后用bitsChanged记录插入结果,如果返回true表明没有重复插入成功。
而mightContain方法则是将索引位置上的数值取出,并判断是否为0,只要其中出现一个0,那么立即判断为不存在。
# 总结
现在对布隆过滤器已经有一个基本的了解,知道它的原理、应用场景、优点和缺点、Java 中可以引用 Guava 包来使用布隆过滤器、以及初步查看知道 Guava 中的一些方法实现。
至于 Guava 中 BloomFilter 的 bits 的 set 和 get ,以及其它的一些更深入具体的实现,等以后有时间再找机会读源码学习。